Sandrart.net: An enriched online edition of a 17th century text
Carsten Blüm, Goethe-Universität Frankfurt am Main
February 23rd, 2012 • Berlin
Agenda
What is “Sandrart.net”?
- Subject
- Goals
- Information on the project itself
What we achieved
Annotations
Some thoughts on lifecycles
The subject

Joachim von Sandrart: “Teutsche Academie der Bau-, Bild- und Mahlerey-Künste”
Nürnberg 1675 / 1679 / 1680
The subject

3 volumes • 1,600 pages (not including blank pages) • 6.9 million characters • Approx. 300 full-page copperplate engravings
The Idea
Goals
In one sentence:
A (partially) annotated web-based edition of the “Teutsche Academie” that assists the user in finding persons and places mentioned in the text and that offers partial translations to other languages.
The project
- Goethe-Universität Frankfurt
- Kunsthistorisches Institut in Florenz – Max-Planck-Institut
- Funded by the Deutsche Forschungsgemeinschaft (DFG)
- April 2007 – March 2012
- Long-time availability: Herzog August Bibliothek Wolfenbüttel (HAB)
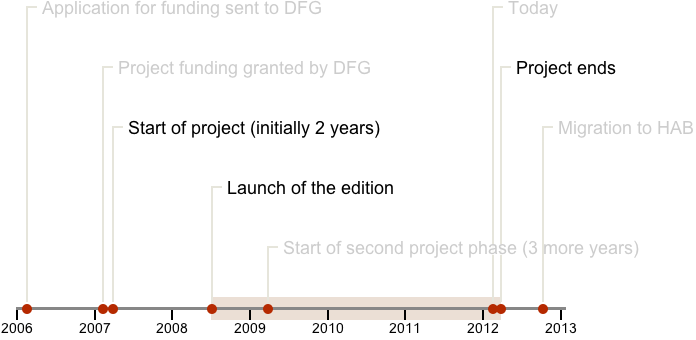
Current state
Resources
- Digitized images available on the web
- Full text available on the web
- Databases of entities mentioned in the text
- More than 5,000 persons
- More than 2,000 places
- More than 2,400 works of art
(+ More than 2,500 additional artworks which provide additional context)
- More than 300 publications and manuscripts mentioned in the text
(+ Bibliography)
- More than 6,000 annotations
- Roughly 30,000 cross-references (triples) between entities
- Partial translations
Current state
Information retrieval
- Faceted search (full-text search, search in annotations, search in databases)
- Individual searches / filtering methods in all databases
- Approx. 60,000 occurrences of persons, places, publications and artworks tagged in the text. Every entity is searchable, regardless of spelling or name used in the text.
Connecting & linking
- Thousands of cross-references to authority files and data sources (PND, ULAN, TGN, Census, VD17, …)
- PND-based cross-references to other sites (“PND BEACON”)
- Permanent URLs (PURLs) for text pages and database entities, incl. annotations
- Web API (proprietary XML/JSON via REST), incl. text occurrences
- Linked Open Data (RDF)
The edition
- Introduction to the edition, starting on page 629
Annotations
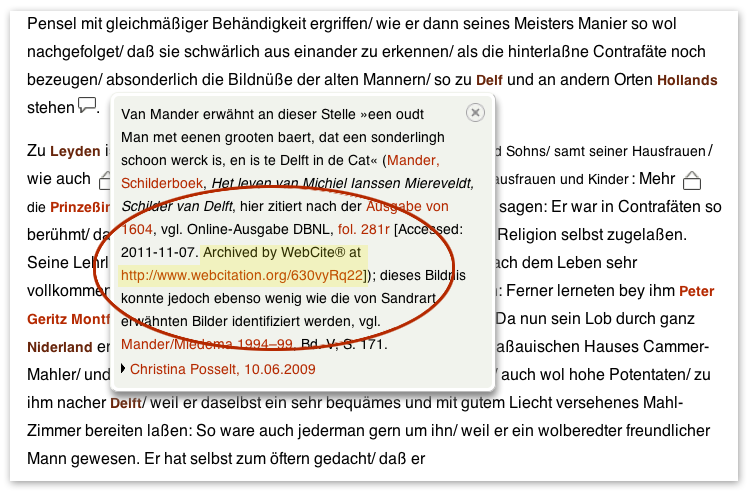
- “Classical” annotations
- Annotations in the context of our project: Information added to things
- Purposes
- Annotations in this broader sense in many places in the edition, also beyond the text
- Why non-textual, machine-readable annotations?
- To sum up: Textual, “classical” annotations are important, but non-textual, machine-readable annotations form the backbone of Sandrart.net
Annotations
The need to be precise
- Contradictory information
- Ambiguous information
- Information that is biased or implies a certain perspective
- Not everything can be expressed
Annotations
The side-effects of complexity
- What about the user?
- What about contributing scholars?
- Can become more difficult to present the information in a useful way.

Annotations
Annotations & “The Cloud”
- Annotations become distributed
- Modern concepts (Linked Open Data, Web APIs, nanopublications, …) can offer new possibilities to enrich your data
- Problem: Increasing dependencies
“A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.”
(Leslie Lamport)
Lifecycle
- Availability of our resources and services
- Availability of external resources
- Problem: consuming/using external data vs. changing content
Lifecycle
Reliable content vs. ongoing development
Benefits
- Get feedback
- Find contributors
- Find cooperations (Deutsches Textarchiv, Herzog-August Bibliothek)
Appendix – In case someone asks: Transcription
Why manual text transcription?
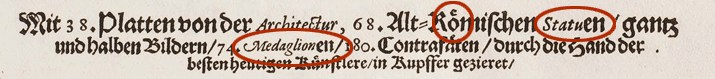
- Mix of Gothic print and Antiqua (even inside words)
- 11 languages
- Inconsistent orthography
- Abbreviations
- Conclusion: OCR not feasible
Appendix – In case someone asks: Tagging
Why manual tagging of entities in the text?
- Ambiguities or ”False friends”
- “Teutscher Apelles” = Joachim von Sandrart, not Apelles
- Errors in seemingly unambiguous names.
For instance: “Benedict IX.” = Benedict XI.
- “Rhenus” could be the river or a personification of the river
- Not only names, but also paraphrases
- No advance knowledge of which entities are in the text
- Large number of different entities, hundreds still not even identified
- Artworks: no formal criteria. Sometimes a single word, sometimes a paragraph
Appendix – In case someone asks: TEI usage
TEI usage
- Physical text structure (volumes, pages, column breaks, …)
- Logical text structure (<div>, <head>, <p>, <argument>, <titlePage>, <lg>, …)
- Objects in the text (persons, places, artworks, publications): <rs type="…">…</rs>
- Small number of other elements used: <sic>, <corr>, <date>, <foreign>, <ref>, <seg>, …
Appendix – In case someone asks: Handling of annotations
Method
- Annotations are saved in a database and only referenced in TEI
- Annotations are “compiled” into TEI
Reasons
- Annotations in entity records are technically identical
- Annotations can be re-used
- When kept in a database, earlier versions can be more easily saved and diff-ed
- Easier searching
- Most simple solution for offering PURLs for annotations and display annotations by themselves
- Annotations become objects in their own right
Appendix – In case someone asks: Implementation
KISS principle: “LAMP”
- Linux (Mac OS OX, other Unices)
- Apache (Lighttpd, Nginx, …)
- MySQL (PostgreSQL, SQLite)
- PHP
“XML shredding”
- Context-aware
- Creating well-formed subsets of the text
Why no XML database?
Appendix – In case someone asks: Context-sensitive Shredding

Appendix – In case someone asks: Changed content
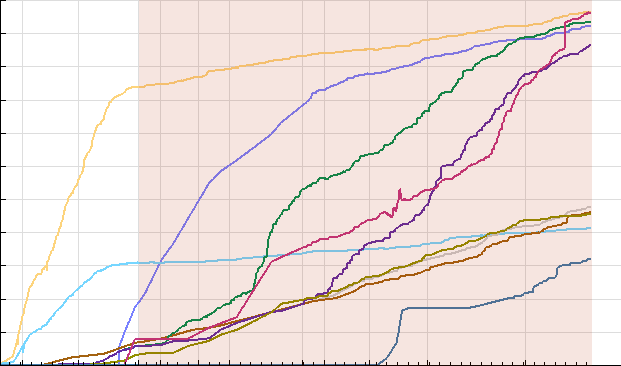
Changes since the first launch of the edition in July 2008
 ←
→
←
→
/
#